Playing Hangman with Deep Reinforcement Learning
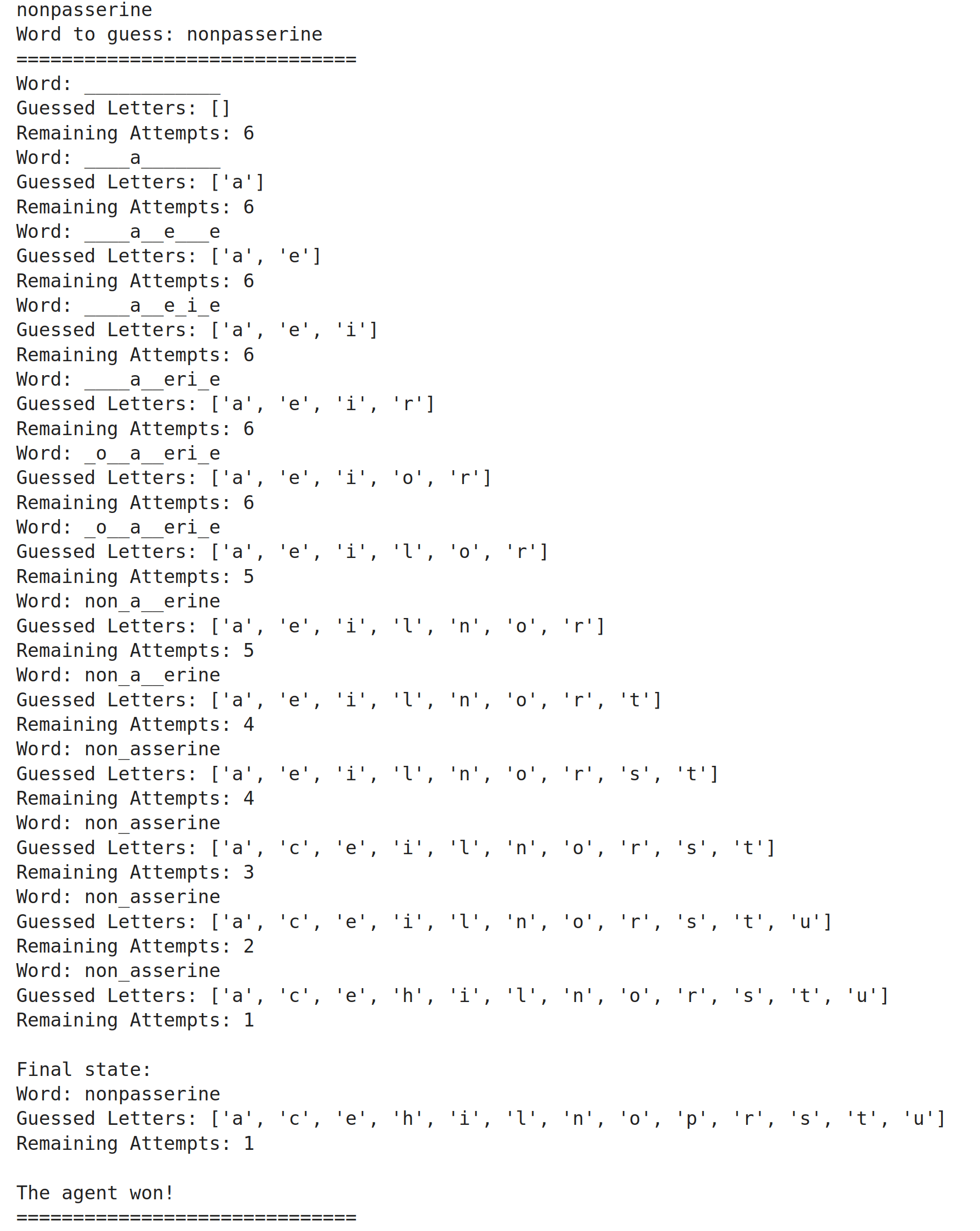
Table of Contents
1. Introduction
2. Background and Prerequisites
3. Setting Up the Development Environment
4. Designing the Hangman Environment
5. Integrating the Reinforcement Learning Model
6. Evaluating and Testing the AI Agent
7. Integrating the AI with the Hangman API
8. Troubleshooting Common Issues
9. Results and Performance Analysis
10. Conclusion
11. Appendix
12. References
1 - Introduction
Welcome to my deep dive into building an intelligent Hangman AI using Reinforcement Learning (RL) with Recurrent Proximal Policy Optimization (Recurrent PPO) and Curriculum Learning. In this blog, I'll walk you through the entire process, from setting up the environment to training and evaluating the AI agent. Whether you're a seasoned machine learning enthusiast or just getting started, this guide is designed to provide you with comprehensive insights and practical code examples to help you create a robust Hangman-playing AI.
1.1 What is Hangman?
Hangman is a classic word-guessing game where one player thinks of a word, and the other tries to guess it by suggesting letters within a certain number of attempts. The game visually represents the progress of the guesses by drawing parts of a "hangman" figure for each incorrect guess. The objective is to guess the entire word correctly before the figure is fully drawn, indicating a loss.
Here's a simple illustration of how Hangman works:
Word: _ _ _ _ _
Guess a letter: e
Word: _ e _ _ _
Incorrect guesses: None
Remaining attempts: 6
As you can see, the game provides feedback on correct and incorrect guesses, helping the player narrow down the possibilities until the word is fully revealed or the attempts are exhausted.
1.2 Why Build an AI for Hangman?
Creating an AI to play Hangman might seem trivial at first glance, but it presents a unique set of challenges that make it an excellent project for exploring advanced machine learning concepts. Here's why building a Hangman AI is beneficial:
- Understanding Reinforcement Learning: Hangman is an environment where an agent can learn through trial and error, making it a perfect candidate for applying RL techniques.
- Sequential Decision Making: The AI must make a series of decisions (guesses) based on the evolving state of the game, which is ideal for training recurrent neural networks.
- Curriculum Learning Application: By progressively increasing the difficulty of the words, we can effectively train the AI to handle more complex scenarios using Curriculum Learning.
- Practical Implementation: Building this AI provides hands-on experience with setting up environments, defining action and observation spaces, and integrating RL algorithms.
Moreover, Hangman serves as a microcosm for many real-world applications where sequential decision-making and adaptive strategies are crucial, such as game playing, natural language processing, and interactive systems.
1.3 Overview of Reinforcement Learning and Recurrent PPO
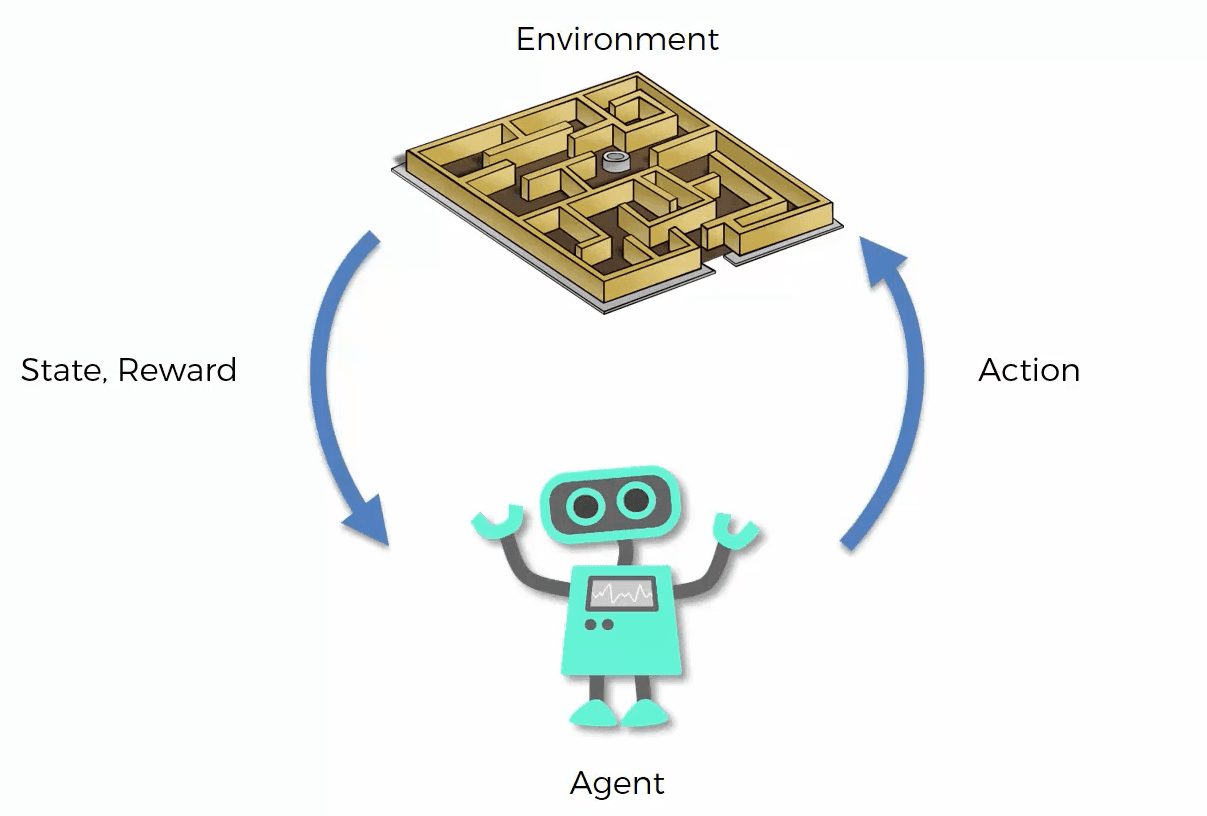
Reinforcement Learning is a subset of machine learning where an agent learns to make decisions by performing actions in an environment to maximize cumulative rewards. Unlike supervised learning, where the model learns from labeled data, RL relies on the agent's interactions with the environment to learn optimal behaviors.
Key Components of RL:
- Agent: The agent is the learner or decision-maker that interacts with the environment. In our Hangman AI project, the agent represents the AI player attempting to guess the hidden word.
- Environment: The environment encompasses everything the agent interacts with. It provides the context within which the agent operates, including the rules of the game and the state of the game at any given time. Learn more about environments in Gymnasium.
- Actions: The set of all possible moves the agent can make (guessing a letter).
- Rewards: Feedback from the environment based on the agent's actions (e.g., correct guess, incorrect guess).
Proximal Policy Optimization (PPO): PPO is a popular policy-based RL algorithm known for its simplicity and effectiveness. It strikes a balance between exploration and exploitation by updating the policy in a way that avoids large deviations from the previous policy, ensuring stable and reliable learning.
Recurrent PPO: When dealing with environments that have temporal dependencies or require memory of past states, integrating recurrent neural networks (like LSTMs) into PPO can significantly enhance performance. Recurrent PPO allows the agent to maintain an internal state, enabling it to make informed decisions based on the history of interactions.
1.4 Benefits of Curriculum Learning in AI Training
Curriculum Learning is a training strategy inspired by the way humans learn, where the learning process starts with simpler tasks and gradually progresses to more complex ones. Implementing Curriculum Learning in training our Hangman AI offers several advantages:
- Improved Learning Efficiency: By starting with easier words, the AI can build foundational knowledge before tackling more challenging scenarios, leading to faster convergence.
- Enhanced Performance: Gradually increasing difficulty helps the agent develop robust strategies that generalize well to various word complexities.
- Avoiding Local Optima: Curriculum Learning helps prevent the agent from getting stuck in suboptimal strategies by exposing it to a diverse set of challenges.
- Better Stability: Training with a structured progression reduces the variance in learning updates, leading to more stable and reliable performance.
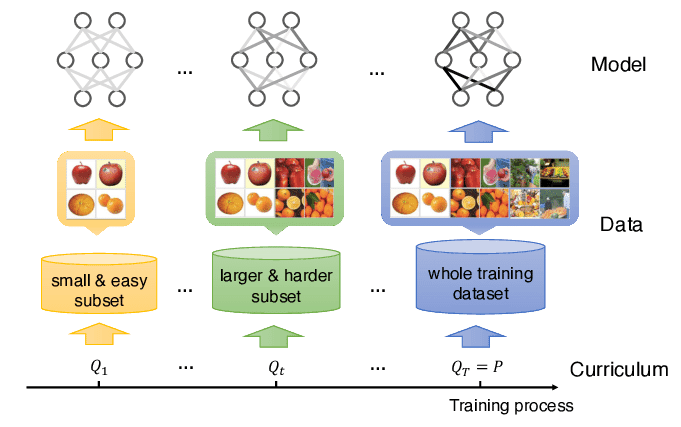
Incorporating Curriculum Learning ensures that our AI doesn't just memorize patterns but truly understands the underlying mechanics of the game, enabling it to adapt and excel in diverse situations.
Throughout the blog, I'll provide detailed code examples, explanations, and insights to ensure you can follow along and replicate the process effectively. Let's embark on this exciting journey to create a Hangman AI that not only plays the game but masters it!
2 - Background and Prerequisites
Before diving into the implementation of the Hangman AI, it's essential to establish a solid understanding of the foundational concepts that underpin this project.
In this section, I'll elucidate the key principles of Reinforcement Learning (RL), delve into the specifics of Recurrent Proximal Policy Optimization (Recurrent PPO), and explore the role of Curriculum Learning in machine learning.
Grasping these concepts will not only aid in comprehending the subsequent sections but also provide valuable insights into the mechanics of training intelligent agents.
2.1. Understanding Reinforcement Learning (RL)
Reinforcement Learning is a dynamic area of machine learning where an agent learns to make decisions by interacting with an environment to achieve specific goals. Unlike supervised learning, which relies on labeled datasets, RL is driven by the agent's experiences and the rewards it receives from its actions.
2.1.1. Key Concepts: Agents, Environments, Rewards
At the heart of RL lie three fundamental components: agents, environments, and rewards. Understanding these elements is crucial for designing and training effective RL models.
-
Agent: The agent is the learner or decision-maker that interacts with the environment. In our Hangman AI project, the agent represents the AI player attempting to guess the hidden word.
-
Environment: The environment encompasses everything the agent interacts with. It provides the context within which the agent operates, including the rules of the game and the state of the game at any given time.
-
Actions: Actions are the set of all possible moves the agent can make within the environment. For Hangman, actions correspond to guessing specific letters.
-
States: A state represents the current situation of the environment. In Hangman, a state includes the current word pattern (e.g.,
_ e _ _ _), the letters already guessed, and the remaining number of attempts. -
Rewards: Rewards are feedback signals from the environment that guide the agent's learning process. Positive rewards encourage desirable actions, while negative rewards discourage undesirable ones. For instance, correctly guessing a letter might yield a positive reward, whereas an incorrect guess could result in a negative reward.
-
Policy: The policy is the strategy that the agent employs to decide its actions based on the current state. It's essentially a mapping from states to actions.
-
Value Function: The value function estimates the expected cumulative reward an agent can obtain from a given state, guiding the agent towards more rewarding states.
Here's a visual representation of these concepts:
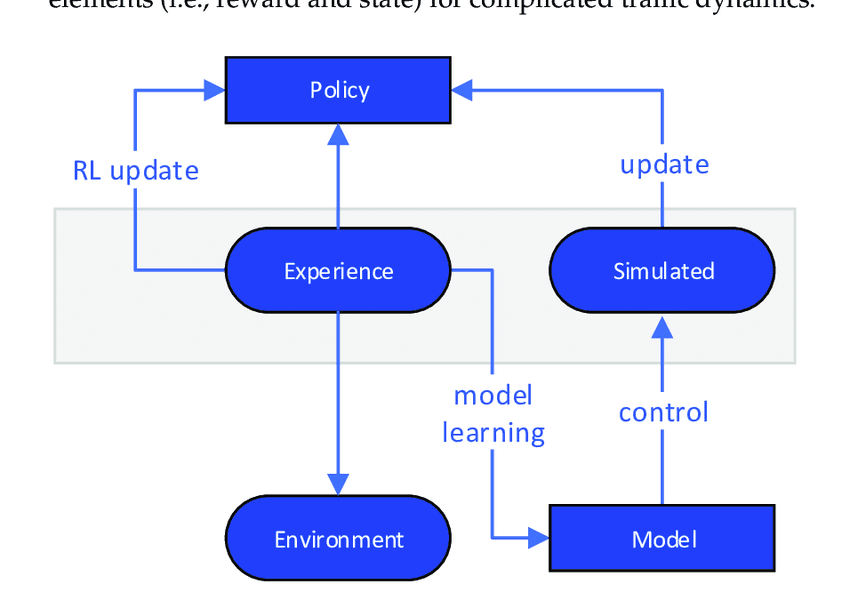
Understanding these components provides a foundation for designing an RL agent capable of mastering Hangman by making informed guesses based on past interactions and rewards received.
2.1.2. Policy-Based Methods
In RL, policies dictate how an agent behaves in an environment. There are primarily two approaches to learning policies: value-based and policy-based methods. Here, we'll focus on policy-based methods, which are particularly suited for environments with large or continuous action spaces.
-
Value-Based Methods: These methods focus on estimating the value function, which in turn guides the agent's policy. Techniques like Q-Learning and Deep Q-Networks (DQN) fall under this category. While effective, value-based methods can struggle with high-dimensional or continuous action spaces.
-
Policy-Based Methods: Instead of estimating the value function, policy-based methods directly optimize the policy itself. This approach is advantageous when dealing with complex action spaces and allows for stochastic policies, which can explore a wider range of actions. Proximal Policy Optimization (PPO) is a popular policy-based algorithm known for its balance between performance and computational efficiency.

Advantages of Policy-Based Methods:
- Handling Large Action Spaces: Policy-based methods are adept at managing environments with vast or continuous action spaces, making them ideal for complex tasks.
- Stochastic Policies: They can naturally handle stochastic policies, enabling the agent to explore different actions and avoid getting stuck in local optima.
- Direct Optimization: By optimizing the policy directly, these methods can converge more reliably in certain environments.
In our Hangman AI project, leveraging a policy-based method like Recurrent PPO allows the agent to efficiently navigate the space of possible letter guesses, adapting its strategy based on the evolving state of the game.
2.2. Recurrent Proximal Policy Optimization (Recurrent PPO)
Building upon the foundation of policy-based methods, Recurrent Proximal Policy Optimization (Recurrent PPO) introduces recurrent neural networks into the PPO framework. This integration is pivotal for tasks that require the agent to maintain a memory of past interactions, such as playing Hangman where previous guesses influence future decisions.
2.2.1. Why Recurrent Networks?
Recurrent Neural Networks (RNNs), and their more sophisticated variants like Long Short-Term Memory (LSTM) networks, are designed to handle sequential data by maintaining an internal state that captures information from previous inputs. This capability is essential in environments where the current state depends on a history of past states and actions.
Necessity in Hangman:
In Hangman, each guess provides new information about the word, and the sequence of guesses determines the agent's strategy. For instance, recognizing that certain letters have been ruled out can inform more strategic future guesses. Without memory, the agent would treat each guess in isolation, potentially leading to inefficient strategies.
By incorporating recurrent networks, Recurrent PPO enables the Hangman AI to remember past guesses and adapt its strategy accordingly, leading to more intelligent and efficient gameplay.
This memory retention allows the AI to make informed decisions based on the sequence of previous actions, enhancing its ability to solve the Hangman game effectively.
2.2.2. Advantages of Recurrent PPO
Recurrent PPO combines the strengths of PPO with the memory capabilities of recurrent networks, offering several advantages:
-
Stability and Reliability: PPO is renowned for its stable training process, balancing exploration and exploitation without making overly large policy updates. This stability is crucial for ensuring consistent performance.
-
Memory Integration: The incorporation of RNNs allows the agent to maintain an internal state, enabling it to consider past interactions when making decisions. This is particularly beneficial for tasks like Hangman, where the context of previous guesses informs future actions.
-
Sample Efficiency: Recurrent PPO can achieve high performance with fewer samples by effectively leveraging the sequential nature of the data, reducing the computational resources required for training.
-
Adaptability: The combination of PPO and recurrent networks makes the agent adaptable to a variety of environments, especially those requiring understanding of temporal dependencies.
-
Scalability: Recurrent PPO scales well with complex environments, making it suitable for more sophisticated applications beyond simple games.
Application in Hangman AI:
By utilizing Recurrent PPO, our Hangman AI can efficiently learn optimal guessing strategies by remembering past guesses and outcomes. This leads to:
- Strategic Guessing: The AI can prioritize letters based on their likelihood of appearing in the word, informed by previous correct and incorrect guesses.
- Efficient Learning: The stable training process ensures that the AI converges to effective strategies without erratic behavior.
- Enhanced Performance: Memory retention enables the AI to adapt its strategy dynamically as the game progresses, improving its chances of winning.
In essence, Recurrent PPO provides the necessary framework for building an intelligent Hangman AI that can learn and adapt its strategies over time, mimicking human-like decision-making processes.
2.3. Curriculum Learning in Machine Learning
Curriculum Learning is an instructional strategy inspired by the way humans learn, where learners are introduced to simpler concepts before gradually progressing to more complex ones. In machine learning, this approach involves training models on easier tasks before tackling harder ones, facilitating more efficient and effective learning.
2.3.1. Concept and Importance
Concept of Curriculum Learning:
The core idea of Curriculum Learning is to structure the training process in a way that aligns with the natural progression of learning. By starting with simpler, more manageable tasks, the model can build a strong foundational understanding before being exposed to more challenging scenarios. This method contrasts with training models on complex tasks from the outset, which can lead to slower convergence and suboptimal performance.
Importance in AI Training:
- Accelerated Learning: Models trained with a curriculum often learn faster because they can grasp basic patterns and concepts before dealing with complexities.
- Improved Generalization: By mastering simple tasks first, models develop robust features that help them generalize better to new, unseen data.
- Enhanced Stability: Gradual complexity reduces the risk of the model getting stuck in poor local minima, leading to more stable training dynamics.
- Efficient Resource Utilization: Curriculum Learning can lead to more efficient use of computational resources by enabling faster convergence and reducing the need for extensive hyperparameter tuning.
Example:
Consider training a Hangman AI. Without a curriculum, the AI might start with long, complex words, making it difficult to learn effective guessing strategies. With Curriculum Learning, we begin by training the AI on shorter words with fewer letters, allowing it to develop basic strategies. As the AI becomes proficient, we gradually introduce longer words with more letters, building on the strategies learned in earlier phases.
2.3.2. Implementing Curriculum Learning
Implementing Curriculum Learning involves designing a sequence of training phases, each introducing a new level of difficulty. Here's how we can approach it:
-
Define Curriculum Phases:
- Phase 1: Start with short words (e.g., 3-5 letters) and allow more attempts.
- Phase 2: Introduce medium-length words (e.g., 6-8 letters) with a slightly reduced number of attempts.
- Phase 3: Move to longer words (e.g., 9-12 letters) with fewer attempts.
- Phase 4: Continue increasing word length and further reducing attempts, gradually ramping up the difficulty.
-
Determine Advancement Criteria:
- Performance-Based Advancement: Advance to the next phase once the agent achieves a certain win rate or efficiency in the current phase.
- Time-Based Advancement: Progress to the next phase after a fixed number of training steps or episodes, regardless of performance.
-
Implement Phase Progression:
- Monitor Performance: Continuously track the agent's performance metrics to decide when to advance or regress phases.
- Adjust Environment Settings: Dynamically modify the environment parameters (e.g., word length range, maximum attempts) based on the current phase.
-
Handle State Persistence:
- Save Curriculum State: Store the current phase and progress to ensure that training can resume seamlessly after interruptions.
- Load Curriculum State: Retrieve the saved state at the beginning of training to maintain continuity.
Implementation in Hangman AI:
In our Hangman AI project, Curriculum Learning is implemented by defining a Curriculum class that manages different training phases. Each phase specifies the range of word lengths and the maximum number of allowed attempts. As the agent demonstrates proficiency in a phase, the curriculum advances, introducing more challenging words and stricter attempt limits. This structured progression ensures that the AI develops robust guessing strategies, enhancing its ability to handle a diverse set of Hangman scenarios.
Benefits Realized:
- Faster Convergence: By starting with simpler tasks, the AI quickly learns basic strategies, accelerating the overall training process.
- Enhanced Strategy Development: Gradually increasing complexity allows the AI to build upon previously learned strategies, leading to more sophisticated decision-making.
- Stable Training Dynamics: Curriculum Learning prevents the AI from being overwhelmed by complexity too early, ensuring a smooth and stable training progression.
Incorporating Curriculum Learning into our Hangman AI not only mirrors the natural learning process but also significantly enhances the agent's performance and adaptability in the game.
With a solid grasp of Reinforcement Learning, Recurrent PPO, and Curriculum Learning, we're now poised to set up our development environment and embark on the journey of building a Hangman AI that can learn, adapt, and excel. Let's move forward to the next section where we'll get our hands dirty with the practical aspects of setting up the tools and preparing the data needed for our AI agent.
3 - Setting Up the Development Environment
Embarking on the journey to build a Hangman AI necessitates a well-configured development environment. In this section, I'll guide you through the essential libraries and dependencies required for our project, as well as the process of preparing and cleaning the word list that our AI will use to learn and make predictions. Let's get started!
3.1. Required Libraries and Dependencies
Before we dive into coding, it's crucial to ensure that our development environment is equipped with all the necessary tools and libraries. These libraries provide the foundational functionalities required for building, training, and evaluating our Reinforcement Learning model.
3.1.1. Installing Gymnasium, Stable Baselines3, and SB3-Contrib
Gymnasium is a toolkit for developing and comparing reinforcement learning algorithms. It provides a wide range of environments, including our custom Hangman environment, facilitating standardized interactions between the agent and the environment.
Stable Baselines3 is a set of reliable implementations of reinforcement learning algorithms in Python. It offers a user-friendly interface and integrates seamlessly with Gymnasium environments.
SB3-Contrib extends Stable Baselines3 by adding experimental and less commonly used algorithms, including Recurrent PPO, which is essential for our project.
To install these libraries, follow the steps below:
-
Ensure Python is Installed:
Make sure you have Python 3.9 or later installed on your system.
-
Set Up a Virtual Environment (Optional but Recommended):
Creating a virtual environment helps manage dependencies and avoid conflicts between different projects.
python -m venv hangman_env
source hangman_env/bin/activate # On Windows, use `hangman_env\Scripts\activate`
- Upgrade pip:
Before installing new packages, it's a good practice to upgrade pip to the latest version.
pip install --upgrade pip
- Install necessary libraries:
pip install gymnasium stable-baselines3[extra] sb3-contrib numpy pandas matplotlib seaborn plotly torch scikit-learn nltk tqdm joblib
3.2. Preparing the Word List
The word list is a critical component of our Hangman AI. It serves as the dataset from which the AI learns and makes guesses. Ensuring that this list is clean, valid, and diverse is paramount for the agent's performance and generalization capabilities.
3.2.1. Loading and Cleaning the Word List
To train our Hangman AI effectively, we need a comprehensive and well-structured word list. This list should consist of a wide variety of words differing in length and complexity. Here's how to load and clean the word list:
-
Loading the Word List:
Typically, word lists are stored in text files with one word per line. We'll load the words into a Python list for easy manipulation.
def load_word_list(file_path):
"""
Loads words from a specified file.
:param file_path: Path to the word list file.
:return: List of words.
"""
with open(file_path, 'r') as file:
words = file.read().splitlines()
return [word.strip().lower() for word in words if word.strip()]
- Cleaning the Word List:
After loading the words, it's essential to clean the list to ensure data quality. Cleaning involves removing duplicates, filtering out non-alphabetic entries, and ensuring a diverse range of word lengths.
def clean_word_list(word_list, min_length=3, max_length=20):
"""
Cleans the word list by filtering out unwanted words.
:param word_list: List of words to clean.
:param min_length: Minimum length of words to include.
:param max_length: Maximum length of words to include.
:return: Cleaned list of words.
"""
cleaned_words = []
for word in word_list:
# Check if the word meets all criteria
if (
min_length <= len(word) <= max_length # Length criteria
and word.isalpha() # Contains only alphabetic characters
and len(set(word)) > 1 # Avoid words with all identical letters
):
cleaned_words.append(word)
return cleaned_words
- Executing the Loading and Cleaning Process:
Combining the above functions, we can load and clean our word list as follows:
# Path to the word list file
file_path = 'words_250000_train.txt'
# Load the raw word list
raw_word_list = load_word_list(file_path)
# Clean the word list
cleaned_word_list = clean_word_list(raw_word_list)
# Optionally, save the cleaned word list for future use
output_file_path = 'cleaned_word_list.txt'
with open(output_file_path, 'w') as file:
file.write('\n'.join(cleaned_word_list))
print(f"Original word count: {len(raw_word_list)}")
print(f"Cleaned word count: {len(cleaned_word_list)}")
- Quality Assurance:
Optionally, cross-reference the word list with a reputable dictionary to ensure the inclusion of valid and commonly used words.
import nltk
from nltk.corpus import words
nltk.download('words')
valid_words = set(w.lower() for w in words.words())
cleaned_words = [word for word in cleaned_words if word in valid_words]
3.2.2. Code Example: Loading and Cleaning Words
To streamline the process of loading and cleaning our word list, here's a comprehensive code example that encapsulates the functions discussed above. This script will read the words from a file, clean them based on predefined criteria, and save the cleaned list for future use.
import nltk
from nltk.corpus import words
# Download the English words corpus
nltk.download("words")
def load_word_list(file_path):
"""
Loads words from a specified file.
:param file_path: Path to the word list file.
:return: List of words.
"""
with open(file_path, 'r') as file:
words_list = file.read().splitlines()
return [word.strip().lower() for word in words_list if word.strip()]
def clean_word_list(word_list, min_length=3, max_length=20):
"""
Cleans the word list by filtering out unwanted words.
:param word_list: List of words to clean.
:param min_length: Minimum length of words to include.
:param max_length: Maximum length of words to include.
:return: Cleaned list of words.
"""
cleaned_words = []
valid_words = set(w.lower() for w in words.words())
for word in word_list:
if (
min_length <= len(word) <= max_length # Length criteria
and word.isalpha() # Contains only alphabetic characters
and len(set(word)) > 1 # Avoid words with all identical letters
and word in valid_words # Valid English word
):
cleaned_words.append(word)
# Remove duplicates
cleaned_words = list(set(cleaned_words))
return cleaned_words
# Path to the word list file
file_path = 'words_250000_train.txt'
# Load the raw word list
raw_word_list = load_word_list(file_path)
# Clean the word list
cleaned_word_list = clean_word_list(raw_word_list)
# Save the cleaned word list to a new file
output_file_path = 'cleaned_word_list.txt'
with open(output_file_path, 'w') as file:
file.write('\n'.join(cleaned_word_list))
print(f"Original word count: {len(raw_word_list)}")
print(f"Cleaned word count: {len(cleaned_word_list)}")
By following the steps outlined above, we've successfully set up our development environment with all the necessary libraries and dependencies. Additionally, we've prepared a clean and diverse word list that will serve as the foundation for training our Hangman AI. In the next section, we'll delve into designing the custom Hangman environment, where the RL agent will interact and learn to play the game effectively.
4 - Designing the Hangman Environment
Creating a robust environment is pivotal for training our Hangman AI effectively. In this section, I'll walk you through designing a custom Gym environment tailored for Hangman, implementing Curriculum Learning to enhance the agent's training progression, and optimizing the environment to facilitate efficient reinforcement learning. By the end of this section, you'll have a comprehensive understanding of how to set up an environment that not only challenges the AI but also supports its learning journey.
4.1. Creating a Custom Gym Environment
Gymnasium (formerly Gym) is a toolkit for developing and comparing reinforcement learning algorithms. It provides a standardized interface for environments, making it easier to integrate different algorithms and environments seamlessly. However, since Hangman isn't a built-in environment, we'll need to create a custom one that aligns with Gym's specifications.
4.1.1. Defining the Action and Observation Spaces
In reinforcement learning, action spaces and observation spaces define the set of possible actions an agent can take and the information it receives from the environment, respectively.
-
Action Space: For Hangman, the actions correspond to guessing letters from the English alphabet. Since there are 26 letters, the action space is discrete with 26 possible actions. Learn more about action spaces in Gymnasium Spaces.
-
Observation Space: The observation should encapsulate all necessary information for the agent to make informed decisions. For Hangman, this includes:
- Revealed Word: The current state of the word with guessed letters revealed and unknown letters hidden.
- Guessed Letters: A record of letters that have already been guessed.
- Remaining Attempts: The number of incorrect guesses remaining.
- Word Length: The length of the target word.
- Letter Frequencies: The frequency of each letter in the word list, which can inform the agent's guessing strategy.
- Last Action: The most recent letter guessed by the agent.
- Unique Letters Remaining: The number of unique letters yet to be guessed.
- Letter Probabilities: Dynamic probabilities of each letter being in the target word based on the current state.
By meticulously defining these spaces, we ensure that the agent has all the information it needs to learn and adapt its guessing strategy effectively.
4.1.2. State Representation and Encoding
Properly encoding the state is crucial for the agent to interpret the environment accurately. Here's how each component of the observation space is represented and encoded:
-
Revealed Word:
- Encoding: Each letter position in the word is represented as an integer. If a letter is revealed, it's encoded as its corresponding index (e.g., 'a' = 0, 'b' = 1, ..., 'z' = 25). Unknown letters are represented by
-1. - Representation: A fixed-size array (based on
max_word_length) where each position holds the encoded value of the letter.
- Encoding: Each letter position in the word is represented as an integer. If a letter is revealed, it's encoded as its corresponding index (e.g., 'a' = 0, 'b' = 1, ..., 'z' = 25). Unknown letters are represented by
-
Guessed Letters:
- Encoding: A binary vector of length 26 where each index represents a letter of the alphabet. A value of
1indicates that the letter has been guessed, while0means it hasn't. - Representation:
numpyarray of floats (0.0or1.0).
- Encoding: A binary vector of length 26 where each index represents a letter of the alphabet. A value of
-
Remaining Attempts:
- Encoding: Normalized to a range between
0and1by dividing by the maximum number of attempts. - Representation: Single float value.
- Encoding: Normalized to a range between
-
Word Length:
- Encoding: Normalized to a range between
0and1by dividing by the maximum word length. - Representation: Single float value.
- Encoding: Normalized to a range between
-
Letter Frequencies:
- Encoding: Represents the probability of each letter appearing in the word list.
- Representation: Float vector of length 26.
-
Last Action:
- Encoding: One-hot encoded vector indicating the last letter guessed.
- Representation: Float vector of length 26.
-
Unique Letters Remaining:
- Encoding: Normalized to a range between
0and1by dividing by the total number of letters. - Representation: Single float value.
- Encoding: Normalized to a range between
-
Letter Probabilities:
- Encoding: Dynamic probabilities recalculated based on the current state of the game.
- Representation: Float vector of length 26.
By combining all these components, we create a comprehensive and informative state vector that the AI can use to make strategic guesses.
4.2. Implementing Curriculum Learning
Curriculum Learning is a training strategy where the agent is exposed to tasks in a structured order, starting with simpler ones and progressively tackling more complex challenges. This approach mirrors human learning and facilitates more efficient and effective training.
4.2.1. Curriculum Phases and Progression
To implement Curriculum Learning in our Hangman environment, we'll define multiple phases, each with varying levels of difficulty. Here's how the phases are structured:
-
Phase 1:
- Word Length Range: 3-6 letters
- Max Attempts: 12
-
Phase 2:
- Word Length Range: 6-8 letters
- Max Attempts: 10
-
Phase 3:
- Word Length Range: 8-10 letters
- Max Attempts: 8
-
Phase 4:
- Word Length Range: 10-12 letters
- Max Attempts: 7
-
Phase 5:
- Word Length Range: 12-15 letters
- Max Attempts: 6
-
Phase 6:
- Word Length Range: 15-20 letters
- Max Attempts: 6
Progression Strategy:
- Performance-Based Advancement: After the agent achieves a predefined success rate in the current phase, it advances to the next phase.
- Termination: The curriculum progresses until the final phase is reached, ensuring the agent is exposed to increasingly challenging scenarios.
4.2.2. Saving and Loading Curriculum State
To ensure that the curriculum's state persists across training sessions, we'll implement state persistence using a JSON file. This allows the training process to resume seamlessly after interruptions.
- Saving State: After advancing to a new phase, the current phase is saved to a JSON file.
- Loading State: Upon initialization, the curriculum checks for an existing state file and loads the current phase if available; otherwise, it starts from Phase 1.
This mechanism ensures continuity in training and prevents the agent from restarting the curriculum from scratch after each session.
4.2.3. Code Example: Curriculum Class Implementation
Below is the implementation of the Curriculum class, which manages the curriculum phases and handles state persistence. This class is pivotal in orchestrating the structured progression of training phases.
import json
class Curriculum:
"""
Manages the curriculum phases for training the Hangman agent with state persistence.
"""
def __init__(self, state_file='curriculum_state.json'):
self.current_phase = 1
self.phases = {
1: {'word_length_range': (3, 6), 'max_attempts': 12},
2: {'word_length_range': (6, 8), 'max_attempts': 10},
3: {'word_length_range': (8, 10), 'max_attempts': 8},
4: {'word_length_range': (10, 12), 'max_attempts': 7},
5: {'word_length_range': (12, 15), 'max_attempts': 6},
6: {'word_length_range': (15, 20), 'max_attempts': 6},
}
self.state_file = state_file
self.load_state()
def get_current_config(self):
return self.phases[self.current_phase]
def advance_phase(self):
if self.current_phase < len(self.phases):
self.current_phase += 1
print(f"Advancing to Phase {self.current_phase}")
self.save_state()
else:
if self.current_phase == len(self.phases):
print("Already in the final curriculum phase.")
def regress_phase(self):
if self.current_phase > 1:
self.current_phase -= 1
print(f"Regressing to Phase {self.current_phase}")
self.save_state()
else:
print("Already in the first curriculum phase.")
def save_state(self):
state = {'current_phase': self.current_phase}
with open(self.state_file, 'w') as f:
json.dump(state, f)
print(f"Curriculum state saved to {self.state_file}")
def load_state(self):
try:
with open(self.state_file, 'r') as f:
state = json.load(f)
self.current_phase = state.get('current_phase', 1)
print(f"Curriculum state loaded: Phase {self.current_phase}")
except FileNotFoundError:
print("No existing curriculum state found. Starting from Phase 1.")
Explanation:
-
Initialization (
__init__): Sets the starting phase and defines the configuration for each phase. It attempts to load an existing state from a JSON file; if none exists, it starts from Phase 1. -
get_current_config: Retrieves the configuration (word length range and maximum attempts) for the current phase. -
advance_phase: Moves the curriculum to the next phase if possible and saves the updated state. -
regress_phase: Allows the curriculum to move back to a previous phase, useful for debugging or adjusting training difficulty. -
save_state: Serializes the current phase to a JSON file, ensuring persistence across training sessions. -
load_state: Deserializes the phase from the JSON file. If the file doesn't exist, it initializes the curriculum at Phase 1.
This Curriculum class provides a structured and persistent way to manage the training phases, ensuring that the Hangman AI is progressively challenged as it learns.
4.3. Optimizing the Environment for RL
Optimizing the Hangman environment is essential to ensure that the reinforcement learning agent can learn efficiently and effectively. This involves handling the game's dynamics appropriately and providing the agent with meaningful feedback.
4.3.1. Handling Revealed and Hidden Letters
Managing the state of revealed and hidden letters is crucial for accurately representing the game's progress to the agent.
-
Revealed Letters: When the agent guesses a correct letter, its positions in the word are revealed. This information helps the agent make more informed guesses in subsequent steps.
-
Hidden Letters: Letters that haven't been guessed yet remain hidden, represented by placeholders (e.g., underscores).
Implementation Details:
- Revealed Word Encoding: Use a fixed-size array (based on
max_word_length) where each position holds the encoded value of the letter if revealed or-1if hidden.
# Revealed word as integer encoding (-1 for unknown, 0-25 for revealed letters)
revealed_word_int = np.full(self.max_word_length, -1.0, dtype=np.float32)
for i in range(self.word_length):
if self.revealed_word[i, 26] == 0:
# Letter is revealed
letter_index = np.argmax(self.revealed_word[i, :26])
revealed_word_int[i] = float(letter_index)
else:
# Letter is hidden
revealed_word_int[i] = -1.0
State Update: After each guess, update the revealed_word array to reflect newly revealed letters.
By accurately tracking revealed and hidden letters, the environment provides the agent with clear and actionable information, enabling it to refine its guessing strategy over time.
4.3.2. Calculating Letter Probabilities Dynamically
Dynamic calculation of letter probabilities enhances the agent's decision-making by providing real-time insights into the likelihood of each letter appearing in the target word.
Why Dynamic Calculation?
-
Adaptive Strategy: As the game progresses and more letters are guessed, the probability distribution of remaining letters changes. Dynamic calculation allows the agent to adapt its strategy based on the current state.
-
Efficiency: Precomputed probabilities may not account for the evolving game state, leading to suboptimal guesses. Dynamic calculation ensures that probabilities are always relevant.
Implementation Details:
- Pattern Matching: Create a regex pattern based on the current state of the revealed word and guessed letters to filter potential candidate words.
# Create a regex pattern based on the revealed word
pattern = ''.join(
[f"[{chr(int(self.revealed_word[i, :26].argmax() + ord('a')))}]" if self.revealed_word[i, 26] == 0 else '.'
for i in range(self.word_length)]
)
regex = re.compile(f"^{pattern}$")
Filtering Candidates: Use the pattern to filter words from the word list that match the current state and exclude words containing any incorrectly guessed letters.
# Filter possible words that match the pattern
possible_words = [word for word in self.word_list if regex.match(word)]
# Exclude words containing any incorrect guessed letters
if self.incorrect_guesses:
possible_words = [word for word in possible_words if not any(letter in word for letter in self.incorrect_guesses)]
Probability Calculation: Count the frequency of each letter in the filtered list of possible words and normalize the counts to obtain probabilities.
# Count the frequency of each letter in the possible words
letter_counts = Counter(''.join(possible_words))
total_letters = sum(letter_counts.values())
probabilities = np.zeros(26, dtype=np.float32)
for i in range(26):
letter = chr(i + ord('a'))
probabilities[i] = letter_counts.get(letter, 0) / total_letters if total_letters > 0 else 0.0
Fallback Mechanism: If no words match the current pattern, assign uniform probabilities to all letters to avoid stalling the agent.
if not possible_words:
# If no words match, assign uniform probabilities
return np.ones(26, dtype=np.float32) / 26
By dynamically calculating letter probabilities, the environment provides the agent with valuable insights that inform its guessing strategy, leading to more intelligent and efficient gameplay.
4.3.3. Full Code Example: HangmanEnv Class
Below is the implementation of the HangmanEnv class, which defines our custom Hangman environment. This class encapsulates the game logic, state management, and reward structure, ensuring seamless interaction with the reinforcement learning agent.
import gymnasium as gym
from gymnasium import spaces
import numpy as np
import random
import re
from collections import Counter
import json
class HangmanEnv(gym.Env):
"""
Optimized Hangman Environment for Reinforcement Learning with Curriculum Learning.
"""
metadata = {'render.modes': ['human']}
def __init__(self, word_list, curriculum, max_word_length=20):
super(HangmanEnv, self).__init__()
self.word_list = word_list
self.max_word_length = max_word_length
# Action space: 26 letters of the alphabet
self.action_space = spaces.Discrete(26)
# Observation space:
# - Revealed word: max_word_length (integer encoding)
# - Guessed letters: 26 (binary vector)
# - Remaining attempts: 1
# - Word length: 1
# - Letter frequencies: 26
# - Last action: 26 (one-hot vector)
# - Unique letters remaining: 1
# - Letter probabilities: 26
obs_size = (
self.max_word_length + # Revealed word
26 + # Guessed letters
1 + # Remaining attempts
1 + # Word length
26 + # Letter frequencies
26 + # Last action
1 + # Unique letters remaining
26 # Letter probabilities
)
self.observation_space = spaces.Box(
low=-1.0, # -1 represents unknown letters
high=25.0, # 'z' is represented by 25
shape=(obs_size,),
dtype=np.float32
)
# Initialize state variables
self.current_word = None
self.guessed_letters = None
self.remaining_attempts = None
self.word_length = None
self.last_action = None
self.unique_letters_remaining = None
# Precompute letter frequencies
self.letter_frequencies = self._compute_letter_frequencies()
# Curriculum instance
self.curriculum = curriculum
# Initialize max_attempts
self.max_attempts = None # Will be set in reset()
# Initialize incorrect guesses
self.incorrect_guesses = set()
def reset(self, word=None, *, seed=None, options=None):
super().reset(seed=seed)
# Get current curriculum configuration
config = self.curriculum.get_current_config()
min_len, max_len = config['word_length_range']
current_max_attempts = config['max_attempts']
# Assign max_attempts based on current phase
self.max_attempts = current_max_attempts
# Reset incorrect guesses
self.incorrect_guesses = set()
# Select a word
if word is not None:
self.current_word = word.lower()
self.word_length = len(self.current_word)
if self.word_length > self.max_word_length:
raise ValueError(f"Word length ({self.word_length}) exceeds max_word_length ({self.max_word_length}).")
if not re.match('^[a-z]+$', self.current_word):
raise ValueError("The word must contain only lowercase letters a-z.")
else:
# Efficiently select a word within the current word length range
eligible_words = [w for w in self.word_list if min_len <= len(w) <= max_len]
if not eligible_words:
raise ValueError("No words found within the current word length range.")
self.current_word = random.choice(eligible_words).lower()
self.word_length = len(self.current_word)
# Initialize revealed word: -1 for unknown, 0-25 for revealed letters
self.revealed_word = np.full((self.max_word_length, 27), -1, dtype=np.int32)
for i in range(self.max_word_length):
if i < self.word_length:
self.revealed_word[i, 26] = 1 # Unknown token
else:
self.revealed_word[i, :] = -1 # Padding
# Initialize guessed letters: 0 for not guessed, 1 for guessed
self.guessed_letters = np.zeros(26, dtype=np.float32)
# Reset remaining attempts based on curriculum
self.remaining_attempts = current_max_attempts
# Reset last action
self.last_action = -1 # No action taken yet
# Calculate unique letters remaining
self.unique_letters_in_word = set(self.current_word)
self.unique_letters_remaining = len(self.unique_letters_in_word)
# Initialize letter probabilities
self.letter_probabilities = self._compute_letter_probabilities()
# Update state
self._update_state()
return self._get_observation(), {}
def _compute_letter_frequencies(self):
"""
Compute the frequency of each letter in the training word list.
"""
all_letters = ''.join(self.word_list)
letter_counts = Counter(all_letters)
total_letters = sum(letter_counts.values())
frequencies = np.zeros(26, dtype=np.float32)
for i in range(26):
letter = chr(i + ord('a'))
frequencies[i] = letter_counts.get(letter, 0) / total_letters if total_letters > 0 else 0.0
return frequencies
def _compute_letter_probabilities(self):
"""
Compute the probability of each letter being in the word given the current state.
Optimized using precompiled regex and vectorized operations.
"""
# Get current word length range from curriculum
config = self.curriculum.get_current_config()
min_len, max_len = config['word_length_range']
# Create a regex pattern based on the revealed word
pattern = ''.join(
[f"[{chr(int(self.revealed_word[i, :26].argmax() + ord('a')))}]" if self.revealed_word[i, 26] == 0 else '.'
for i in range(self.word_length)]
)
regex = re.compile(f"^{pattern}$")
# Filter possible words that match the pattern
possible_words = [word for word in self.word_list if regex.match(word)]
# Exclude words containing any incorrect guessed letters
if self.incorrect_guesses:
possible_words = [word for word in possible_words if not any(letter in word for letter in self.incorrect_guesses)]
if not possible_words:
# If no words match, assign uniform probabilities
return np.ones(26, dtype=np.float32) / 26
# Count the frequency of each letter in the possible words
letter_counts = Counter(''.join(possible_words))
total_letters = sum(letter_counts.values())
probabilities = np.zeros(26, dtype=np.float32)
for i in range(26):
letter = chr(i + ord('a'))
probabilities[i] = letter_counts.get(letter, 0) / total_letters if total_letters > 0 else 0.0
return probabilities
def _word_matches(self, word):
"""
Check if the word matches the current revealed word and hasn't been eliminated.
"""
if len(word) != self.word_length:
return False
for idx, char in enumerate(word):
if self.revealed_word[idx, 26] == 0:
# Letter is revealed; must match
revealed_letter_index = np.argmax(self.revealed_word[idx, :26])
if ord(char) - ord('a') != revealed_letter_index:
return False
else:
# Letter is hidden; must not have been guessed if it's not in the word
if self.guessed_letters[ord(char) - ord('a')] == 1.0 and char not in self.current_word:
return False
return True
def step(self, action):
done = False
reward = 0
# Validate action
if not self.action_space.contains(action):
raise ValueError(f"Invalid action: {action}")
# Map action to corresponding letter
letter = chr(action + ord('a'))
# Update last action
self.last_action = action
# Compute letter probabilities based on current state
self.letter_probabilities = self._compute_letter_probabilities()
# Get the probability of the current action
letter_prob = self.letter_probabilities[action]
# Check if the letter has already been guessed
if self.guessed_letters[action] == 1.0:
# Invalid action selected
reward -= 10 # Significant penalty for invalid action
self.remaining_attempts -= 1 # Decrease remaining attempts
# Check if the agent has run out of attempts
if self.remaining_attempts <= 0:
reward -= 20 # Penalty for losing the game
done = True
else:
# Update guessed letters
self.guessed_letters[action] = 1.0
# Check if the guessed letter is in the word
if letter in self.current_word:
# Correct guess
indices = [i for i, l in enumerate(self.current_word) if l == letter]
new_letters_revealed = 0
for idx in indices:
if self.revealed_word[idx, 26] == 1:
new_letters_revealed += 1
# Reveal the letter
self.revealed_word[idx, :] = -1 # Reset previous state
self.revealed_word[idx, action] = 0 # Encode revealed letter
self.revealed_word[idx, 26] = 0 # Reset unknown token
# Reward for each new letter revealed
reward += 5 * new_letters_revealed
# Additional reward based on letter probability
reward += 10 * letter_prob # Heuristic-based reward
# Update unique letters remaining
self.unique_letters_in_word.discard(letter)
self.unique_letters_remaining = len(self.unique_letters_in_word)
# Check if the word is completely revealed
if self.unique_letters_remaining == 0:
# Efficiency bonus: reward proportional to remaining attempts
efficiency_bonus = 10 * (self.remaining_attempts / self.max_attempts)
reward += 50 + efficiency_bonus # Increased reward for winning
done = True
else:
# Incorrect guess
self.remaining_attempts -= 1
reward -= 2 # Increased penalty
# Additional penalty based on letter probability
reward -= 5 * (1 - letter_prob) # Heuristic-based penalty
# Track incorrect guess
self.incorrect_guesses.add(letter)
# Check if the agent has run out of attempts
if self.remaining_attempts <= 0:
reward -= 20 # Increased penalty for losing
done = True
# Update state
self._update_state()
# Prepare observation
observation = self._get_observation()
# In gymnasium, return (observation, reward, terminated, truncated, info)
terminated = done
truncated = False # Assuming no truncation
info = {}
return observation, reward, terminated, truncated, info
def _update_state(self):
"""
Update normalized state variables and last action vector.
"""
# Normalize remaining attempts
self.normalized_attempts = self.remaining_attempts / self.max_attempts
# Normalize word length
self.normalized_word_length = self.word_length / self.max_word_length
# Normalize unique letters remaining
self.normalized_unique_letters_remaining = self.unique_letters_remaining / 26
# One-hot encode the last action
self.last_action_vec = np.zeros(26, dtype=np.float32)
if self.last_action >= 0:
self.last_action_vec[self.last_action] = 1.0
def _get_observation(self):
"""
Construct the observation vector.
"""
# Revealed word as integer encoding (-1 for unknown, 0-25 for revealed letters)
revealed_word_int = np.full(self.max_word_length, -1.0, dtype=np.float32)
for i in range(self.word_length):
if self.revealed_word[i, 26] == 0:
# Letter is revealed
letter_index = np.argmax(self.revealed_word[i, :26])
revealed_word_int[i] = float(letter_index)
else:
# Letter is hidden
revealed_word_int[i] = -1.0
# Guessed letters as binary vector (0.0 or 1.0)
guessed_letters_binary = self.guessed_letters.astype(np.float32)
# Remaining attempts (normalized between 0 and 1)
remaining_attempts = np.array([self.normalized_attempts], dtype=np.float32)
# Word length (normalized between 0 and 1)
word_length = np.array([self.normalized_word_length], dtype=np.float32)
# Letter frequencies (float32)
letter_frequencies = self.letter_frequencies.astype(np.float32)
# Last action vector (one-hot encoded)
last_action_vector = self.last_action_vec.astype(np.float32)
# Unique letters remaining (normalized between 0 and 1)
unique_letters_remaining = np.array([self.normalized_unique_letters_remaining], dtype=np.float32)
# Letter probabilities (float32)
letter_probabilities = self.letter_probabilities.astype(np.float32)
# Concatenate all components into a single observation vector
observation = np.concatenate([
revealed_word_int, # Revealed word
guessed_letters_binary, # Guessed letters
remaining_attempts, # Remaining attempts
word_length, # Word length
letter_frequencies, # Letter frequencies
last_action_vector, # Last action
unique_letters_remaining, # Unique letters remaining
letter_probabilities # Letter probabilities
])
return observation
def render(self, mode='human'):
"""
Render the current state of the game.
"""
# Displayed word with underscores for unknown letters
displayed_word = ''
for i in range(self.word_length):
if self.revealed_word[i, 26] == 1:
displayed_word += '_'
else:
letter_index = np.argmax(self.revealed_word[i, :26])
displayed_word += chr(letter_index + ord('a'))
print(f"Word: {displayed_word}")
# List of guessed letters
guessed_letters_list = [chr(i + ord('a')) for i in range(26) if self.guessed_letters[i] == 1.0]
print(f"Guessed Letters: {guessed_letters_list}")
# Remaining attempts
print(f"Remaining Attempts: {self.remaining_attempts}")
def close(self):
pass
Explanation:
-
Initialization (
__init__): Sets up the action and observation spaces, initializes state variables, computes letter frequencies, and integrates theCurriculuminstance to manage training phases. -
Reset Function (
reset): Resets the environment to start a new game. It selects a word based on the current curriculum phase, initializes the revealed word, guessed letters, remaining attempts, and calculates letter probabilities. -
Step Function (
step): Handles the agent's action (guessing a letter), updates the game state based on whether the guess is correct or incorrect, calculates rewards, and determines if the game has ended. -
Observation Construction (
_get_observation): Compiles all relevant information into a single observation vector that the agent receives after each action. -
Rendering (
render): Provides a human-readable representation of the current game state, displaying the revealed word, guessed letters, and remaining attempts. -
Letter Probability Calculation (
_compute_letter_probabilities): Dynamically calculates the probability of each letter being in the target word based on the current state, aiding the agent in making informed guesses.
4.3.4. Reward Shaping in HangmanEnv
Reward shaping is a pivotal aspect of reinforcement learning that involves designing the reward signals to encourage desired behaviors and discourage undesired ones. In the context of the HangmanEnv class, reward shaping plays a crucial role in guiding the AI agent to make intelligent guesses, learn efficiently, and achieve the game's objectives. Here's an in-depth look at how reward shaping is implemented in this environment:
a. Overview of Reward Structure
The reward structure in HangmanEnv is meticulously crafted to:
- Encourage Correct Guesses: Reward the agent for correctly identifying letters in the target word.
- Discourage Repeated or Invalid Guesses: Penalize the agent for guessing letters it has already tried or for invalid actions.
- Promote Efficient Learning: Provide bonuses for solving the word quickly and penalties for taking too many attempts.
- Balance Exploration and Exploitation: Use heuristic-based rewards and penalties to guide the agent's learning process.
b. Detailed Reward Shaping Mechanisms
-
Invalid Actions:
- Scenario: The agent selects a letter it has already guessed.
- Reward: A significant penalty of
-10. - Purpose: Discourages the agent from repeating guesses, which do not contribute to solving the game and waste attempts.
- Implementation:
if self.guessed_letters[action] == 1.0:
# Invalid action selected
reward -= 10 # Significant penalty for invalid action
self.remaining_attempts -= 1 # Decrease remaining attempts
...
- Incorrect Guesses:
- Scenario: The agent guesses a letter not present in the target word.
- Reward: A penalty of
-2plus an additional heuristic-based penalty proportional to the inverse probability of the guessed letter. - Purpose: Discourages the agent from making incorrect guesses, thereby conserving attempts.
- Implementation:
else:
# Incorrect guess
self.remaining_attempts -= 1
reward -= 2 # Increased penalty
reward -= 5 * (1 - letter_prob) # Heuristic-based penalty
...
- Correct Guesses:
- Scenario: The agent correctly identifies one or more letters in the target word.
- Reward:
5points for each new letter revealed.- An additional
10points multiplied by the probability of the guessed letter (letter_prob).
- Purpose: Rewards the agent for making correct guesses and leverages the letter probability to encourage strategic guessing.
- Implementation:
if letter in self.current_word:
# Correct guess
...
reward += 5 * new_letters_revealed
reward += 10 * letter_prob # Heuristic-based reward
...
- Winning the Game:
- Scenario: The agent successfully reveals all unique letters in the target word before exhausting all attempts.
- Reward:
- A substantial bonus of
50points. - An efficiency bonus proportional to the remaining attempts (
10 * (self.remaining_attempts / self.max_attempts)).
- A substantial bonus of
- Purpose: Strongly incentivizes the agent to solve the game efficiently, balancing speed and resource conservation.
- Implementation:
if self.unique_letters_remaining == 0:
# Efficiency bonus: reward proportional to remaining attempts
efficiency_bonus = 10 * (self.remaining_attempts / self.max_attempts)
reward += 50 + efficiency_bonus # Increased reward for winning
done = True
- Losing the Game:
- Scenario: The agent fails to reveal all letters within the allowed number of attempts.
- Reward: An additional penalty of
-20. - Purpose: Discourages the agent from failing to solve the game and reinforces the importance of making correct guesses.
- Implementation:
if self.remaining_attempts <= 0:
reward -= 20 # Increased penalty for losing
done = True
c. Rationale Behind Reward Shaping Choices
-
Balance Between Positive and Negative Rewards: The environment provides a mix of rewards and penalties to create a balanced learning signal. Positive rewards for correct actions encourage the agent to repeat beneficial behaviors, while penalties for incorrect or invalid actions prevent the agent from adopting suboptimal strategies.
-
Heuristic-Based Adjustments: Incorporating heuristic factors, such as letter probabilities, allows the agent to prioritize more likely beneficial actions. This guides the agent towards smarter guessing strategies rather than random or repetitive actions.
-
Encouraging Efficiency: By rewarding the agent more for solving the game with remaining attempts, we promote not just success but also efficiency. This aligns with real-world applications where resource optimization is crucial.
-
Preventing Stagnation: Significant penalties for invalid actions ensure that the agent doesn't get stuck in loops of repeating the same guesses, which could hinder the learning process.
d. Impact on Learning and Performance
The meticulously designed reward shaping in HangmanEnv significantly influences the agent's learning trajectory:
-
Accelerated Learning: Clear and immediate rewards for correct actions help the agent quickly identify and reinforce successful strategies.
-
Strategic Decision-Making: Heuristic-based rewards encourage the agent to consider the probability of each action, leading to more informed and strategic guesses.
-
Avoidance of Pitfalls: Penalties for invalid or incorrect actions deter the agent from engaging in unproductive behaviors, ensuring that its learning process remains focused and efficient.
-
Enhanced Performance Metrics: With such a reward structure, the agent is more likely to achieve higher win rates and greater efficiency, as reflected in metrics like average steps per game.
By explicitly incorporating reward shaping into the HangmanEnv class, we've crafted an environment that not only challenges the AI agent but also guides it towards intelligent and efficient learning. This strategic approach to reward design is fundamental in developing robust reinforcement learning models capable of mastering complex tasks.
By meticulously managing the game state and providing a comprehensive observation vector, the HangmanEnv class ensures that the reinforcement learning agent has all the necessary information to learn and adapt its guessing strategies effectively.
With the Hangman environment meticulously designed and integrated with Curriculum Learning, we're now equipped to proceed to the next phase: integrating the reinforcement learning model. In the upcoming section, we'll explore how to configure and train the Recurrent PPO model to master the game of Hangman.
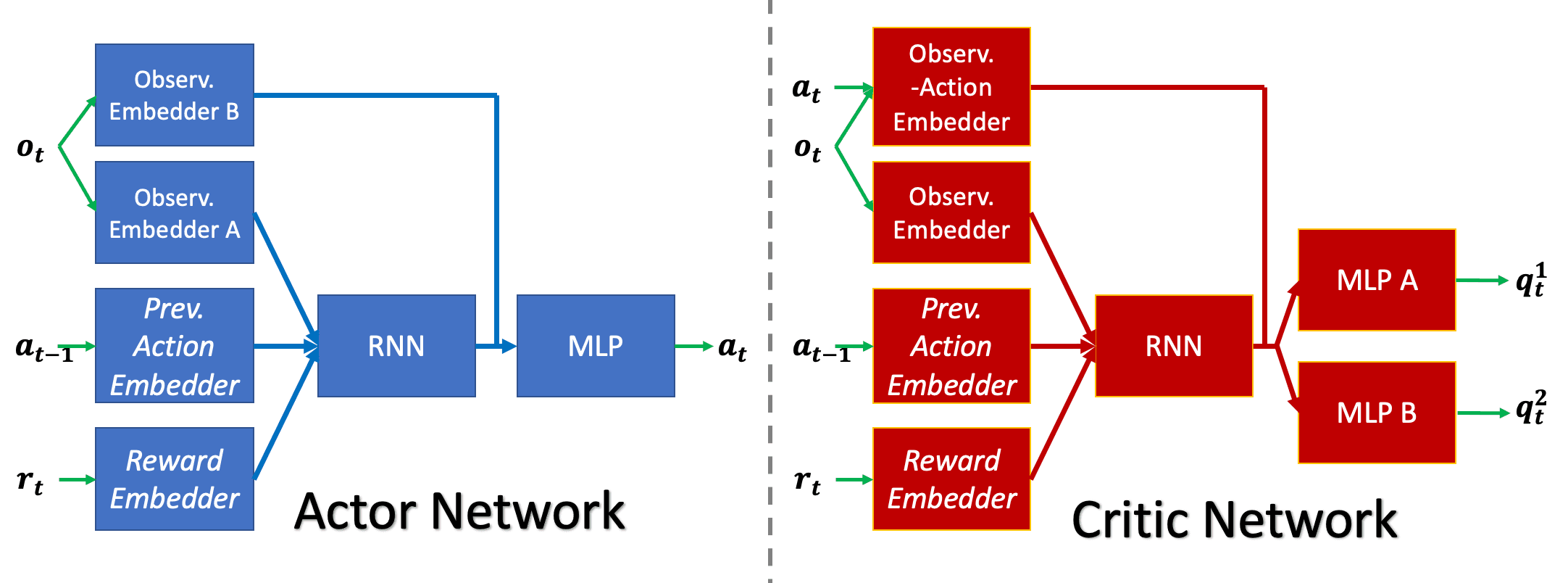
5 - Integrating the Reinforcement Learning Model
With the Hangman environment meticulously designed and integrated with Curriculum Learning, it's time to bring our Reinforcement Learning (RL) model into the picture. In this section, I'll guide you through selecting the appropriate policy architecture, setting up essential callbacks to enhance training, and initializing and training the Recurrent Proximal Policy Optimization (Recurrent PPO) model. By the end of this section, you'll have a fully integrated RL model poised to master the game of Hangman.
5.1. Choosing the Right Policy Architecture
Selecting the appropriate policy architecture is crucial for the success of our RL agent. The policy architecture determines how the agent processes information from the environment and makes decisions based on that information.
5.1.1. MlpLstmPolicy Explained
MlpLstmPolicy is a policy architecture that combines Multi-Layer Perceptrons (MLPs) with Long Short-Term Memory (LSTM) networks. This hybrid approach leverages the strengths of both architectures to handle complex, sequential decision-making tasks effectively.
-
Multi-Layer Perceptron (MLP): An MLP is a class of feedforward artificial neural network that consists of multiple layers of nodes, each fully connected to the next layer. MLPs are excellent for capturing nonlinear relationships in data and are widely used in various machine learning tasks.
-
Long Short-Term Memory (LSTM): An LSTM is a type of Recurrent Neural Network (RNN) capable of learning long-term dependencies in sequential data. LSTMs maintain an internal state that captures information from previous time steps, making them ideal for tasks where context and history are essential.
Why MlpLstmPolicy for Hangman?
Hangman is inherently a sequential game where each guess affects subsequent decisions. The agent must remember previous guesses and their outcomes to make informed future guesses. By integrating LSTM into the policy architecture, MlpLstmPolicy enables the agent to maintain a memory of past actions and observations, enhancing its ability to strategize effectively over the course of the game.
Key Features of MlpLstmPolicy:
- Sequential Decision Making: The LSTM component allows the agent to process sequences of actions and observations, maintaining context throughout the game.
- Enhanced Memory: The internal state of the LSTM captures past interactions, enabling the agent to recall previous guesses and their results.
- Robust Learning: Combining MLPs with LSTMs provides a powerful framework for capturing both local and global patterns in the data.
By choosing MlpLstmPolicy, we're equipping our Hangman AI with the necessary tools to handle the game's sequential nature, ensuring that it can learn and adapt its strategy based on the evolving state of the game.
5.1.2. Policy Keyword Arguments
Policy keyword arguments (policy_kwargs) allow us to customize the architecture and behavior of the policy network. Fine-tuning these parameters can significantly impact the agent's learning efficiency and performance.
Key Components of policy_kwargs:
-
Activation Function (
activation_fn):- Description: Specifies the activation function used in the neural network layers.
- Common Choices: ReLU (
nn.ReLU), Tanh (nn.Tanh), Sigmoid (nn.Sigmoid). - Recommendation: ReLU is often preferred for its simplicity and effectiveness in mitigating vanishing gradient problems.
-
Network Architecture (
net_arch):- Description: Defines the structure of the neural network, including the number of layers and the number of units in each layer.
Example:
net_arch=dict(pi=[256, 128], vf=[256, 128])
-
pi: Architecture for the policy network. -
vf: Architecture for the value function network. -
Recommendation: Deeper networks with more units can capture complex patterns but may require more computational resources.- LSTM Configuration (
lstm_hidden_size,n_lstm_layers,shared_lstm,enable_critic_lstm): -
lstm_hidden_size: Number of hidden units in the LSTM layer.- Example:
lstm_hidden_size=128
- Example:
-
n_lstm_layers: Number of LSTM layers stacked together.- Example:
n_lstm_layers=1
- Example:
-
shared_lstm: Determines whether the LSTM layers are shared between the policy and value networks.- Example:
shared_lstm=True
- Example:
-
enable_critic_lstm: Specifies whether to enable LSTM layers in the critic network.- Example:
enable_critic_lstm=False
- Example:
-
Recommendation: Start with a single LSTM layer and a hidden size of 128. Adjust based on performance and computational constraints.
Example policy_kwargs Configuration:
policy_kwargs = dict(
activation_fn=nn.ReLU,
net_arch=dict(pi=[256, 128], vf=[256, 128]),
lstm_hidden_size=128,
n_lstm_layers=1,
shared_lstm=True,
enable_critic_lstm=False,
)
Explanation:
- Activation Function: ReLU is chosen for its effectiveness in deep networks.
- Network Architecture: Both the policy (
pi) and value (vf) networks have two layers with 256 and 128 units, respectively. - LSTM Configuration: A single LSTM layer with 128 hidden units is used, shared between the policy and value networks, and the critic (value function) does not have its own LSTM layers.
By carefully configuring policy_kwargs, we tailor the policy architecture to suit the specific demands of the Hangman environment, balancing complexity and computational efficiency to achieve optimal learning outcomes.
5.2. Setting Up Callbacks for Training
Callbacks are essential tools in training RL models as they allow us to execute custom code at various stages of the training process. They can be used for monitoring performance, adjusting training parameters, implementing curriculum learning, and saving model checkpoints. Setting up effective callbacks can significantly enhance the training efficiency and the agent's performance.
5.2.1. Curriculum Callback
The Curriculum Callback is responsible for managing the progression of training phases based on predefined criteria. It monitors the number of timesteps and advances the curriculum phase when the agent reaches specific milestones.
Functionality:
- Phase Advancement: Moves the curriculum to the next phase after a certain number of timesteps.
- State Management: Ensures that the curriculum state is saved and loaded appropriately to maintain continuity across training sessions.
5.2.2. Average Reward Callback
The Average Reward Callback monitors the agent's performance by calculating the average reward over a specified number of steps. This provides insights into how well the agent is learning and helps in making informed decisions about training adjustments.
Functionality:
- Performance Monitoring: Calculates and logs the average reward over recent steps.
- Feedback Mechanism: Provides real-time feedback on the agent's learning progress, allowing for dynamic adjustments if necessary.
5.2.3. Checkpoint Callback
The Checkpoint Callback periodically saves the model's state to disk, ensuring that progress isn't lost in case of interruptions. It also allows for model evaluation and selection based on performance.
Functionality:
- Model Saving: Saves the agent's model at regular intervals (e.g., every 50,000 steps).
- Versioning: Helps in maintaining different versions of the model for comparison and rollback purposes.
5.2.4. Code Example: Custom Callback Classes
Below is the implementation of custom callback classes: CurriculumCallback and AverageRewardCallback. These callbacks integrate seamlessly with the Stable Baselines3 framework, enabling advanced training management for our Hangman AI.
from stable_baselines3.common.callbacks import BaseCallback
import numpy as np
class CurriculumCallback(BaseCallback):
"""
A custom callback to manage curriculum learning by advancing phases based on training steps.
"""
def __init__(self, curriculum, phase_timesteps, verbose=1):
"""
:param curriculum: Instance of Curriculum class.
:param phase_timesteps: List of timesteps at which to advance the curriculum phases.
:param verbose: Verbosity level.
"""
super(CurriculumCallback, self).__init__(verbose)
self.curriculum = curriculum
self.phase_timesteps = phase_timesteps
self.current_phase_index = 0
def _on_step(self) -> bool:
"""
Called at every step. Checks if it's time to advance the curriculum.
"""
if self.current_phase_index >= len(self.phase_timesteps):
return True # No more phases to advance
if self.num_timesteps >= self.phase_timesteps[self.current_phase_index]:
self.curriculum.advance_phase()
self.current_phase_index += 1
return True
class AverageRewardCallback(BaseCallback):
"""
A custom callback that logs average reward over a specified number of steps.
"""
def __init__(self, check_freq: int, verbose=0):
super(AverageRewardCallback, self).__init__(verbose)
self.check_freq = check_freq
self.rewards = []
self.total_steps = 0
def _on_step(self) -> bool:
# Safely collect rewards
rewards = self.locals.get('rewards', [])
if len(rewards) > 0:
reward = rewards[0]
self.rewards.append(reward)
self.total_steps += 1
# Check if it's time to compute the average reward
if self.total_steps % self.check_freq == 0:
avg_reward = np.mean(self.rewards[-self.check_freq:])
print(f"Average reward over last {self.check_freq} steps: {avg_reward:.2f}")
return True
Explanation:
-
CurriculumCallback:
- Initialization (
__init__): Takes an instance of theCurriculumclass and a list of timesteps (phase_timesteps) at which to advance the training phases. _on_stepMethod: At each training step, checks if the current number of timesteps has reached the next phase's threshold. If so, it advances the curriculum phase and updates the phase index.
- Initialization (
-
AverageRewardCallback:
- Initialization (
__init__): Accepts a frequency (check_freq) determining how often to calculate and log the average reward. _on_stepMethod: Collects rewards at each step, and everycheck_freqsteps, calculates and prints the average reward over the lastcheck_freqsteps.
- Initialization (
Usage:
These custom callbacks can be combined with other callbacks (like CheckpointCallback) using CallbackList to manage multiple aspects of the training process simultaneously.
from stable_baselines3.common.callbacks import CallbackList, CheckpointCallback
# Define when to advance phases (e.g., after 800k, 1.6M, 2.4M, 3.2M, and 4M timesteps)
phase_timesteps = [800_000, 1_600_000, 2_400_000, 3_200_000, 4_000_000]
# Initialize the CurriculumCallback
curriculum_callback = CurriculumCallback(
curriculum=curriculum,
phase_timesteps=phase_timesteps,
verbose=1
)
# Initialize the AverageRewardCallback
average_reward_callback = AverageRewardCallback(check_freq=5000, verbose=1)
# Define the CheckpointCallback to save models periodically
checkpoint_callback = CheckpointCallback(
save_freq=50_000, # Save every 50,000 steps
save_path='./PPO_LSTM_MORE_ROUNDS/', # Directory to save models
name_prefix='hangman_model_PPO_LSTM', # Prefix for saved model files
save_replay_buffer=False, # Not needed for PPO
save_vecnormalize=False # Not needed if VecNormalize not used
)
# Combine all callbacks
callback = CallbackList([curriculum_callback, average_reward_callback, checkpoint_callback])
By implementing these custom callbacks, we gain granular control over the training process, enabling dynamic curriculum progression, performance monitoring, and regular model checkpointing. This structured approach ensures that our Hangman AI trains efficiently and effectively, adapting its strategy as it progresses through increasingly challenging phases.
5.3. Initializing and Training the Recurrent PPO Model
With the environment and callbacks set up, the next step is to initialize the Recurrent PPO model and commence the training process. This involves configuring hyperparameters, setting up the training loop, and monitoring the agent's progress.
5.3.1. Configuring Hyperparameters
Hyperparameters play a pivotal role in the training process, influencing the agent's learning efficiency and performance. Selecting appropriate hyperparameters requires a balance between computational resources and desired performance outcomes.
Key Hyperparameters:
-
Learning Rate (
learning_rate):- Description: Determines the step size at each iteration while moving toward a minimum of the loss function.
- Typical Values:
1e-4to3e-4 - Recommendation: Start with
1e-4and adjust based on training stability and convergence speed.
-
Number of Steps (
n_steps):- Description: The number of steps to run for each environment per update.
- Typical Values:
128to2048 - Recommendation:
256strikes a good balance between learning stability and computational efficiency.
-
Batch Size (
batch_size):- Description: The number of samples per gradient update.
- Typical Values:
32to1024 - Recommendation:
128is a reasonable starting point.
-
Number of Epochs (
n_epochs):- Description: The number of times to update the policy per batch of data.
- Typical Values:
3to10 - Recommendation:
4provides a good trade-off between learning speed and stability.
-
Discount Factor (
gamma):- Description: Determines the importance of future rewards.
- Typical Values:
0.95to0.99 - Recommendation:
0.99emphasizes long-term rewards, which is suitable for strategic games like Hangman.
-
GAE Lambda (
gae_lambda):- Description: Used in Generalized Advantage Estimation to reduce variance.
- Typical Values:
0.95to0.99 - Recommendation:
0.95is effective for balancing bias and variance.
-
Clip Range (
clip_range):- Description: Clipping parameter for the PPO objective function to ensure stable updates.
- Typical Values:
0.1to0.3 - Recommendation:
0.2is commonly used and provides stability.
-
Entropy Coefficient (
ent_coef):- Description: Encourages exploration by penalizing certainty.
- Typical Values:
0.0to0.05 - Recommendation:
0.01promotes adequate exploration without hindering convergence.
-
Value Function Coefficient (
vf_coef):- Description: Balances the loss between the value function and the policy.
- Typical Values:
0.5to1.0 - Recommendation:
0.5provides a balanced approach.
-
Maximum Gradient Norm (
max_grad_norm):- Description: Clipping parameter for gradient normalization to prevent exploding gradients.
- Typical Values:
0.5to1.0 - Recommendation:
0.5ensures stable training without overly constraining updates.
-
Device (
device):- Description: Specifies whether to use CPU or GPU for training.
- Options:
'cpu'or'cuda' - Recommendation: Use
'cuda'if a GPU is available for faster training.
Example Configuration:
policy_kwargs = dict(
activation_fn=nn.ReLU,
net_arch=dict(pi=[256, 128], vf=[256, 128]),
lstm_hidden_size=128,
n_lstm_layers=1,
shared_lstm=True,
enable_critic_lstm=False,
)
model = RecurrentPPO(
"MlpLstmPolicy",
vec_train_env,
policy_kwargs=policy_kwargs,
learning_rate=1e-4,
n_steps=256,
batch_size=128,
n_epochs=4,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.2,
ent_coef=0.01,
vf_coef=0.5,
max_grad_norm=0.5,
verbose=0,
device=device,
tensorboard_log="./PPO_Hangman_tensorboard/"
)
Explanation:
- Policy Architecture: Utilizes
MlpLstmPolicywith specified network architecture and LSTM configurations. - Learning Rate: Set to
1e-4for stable learning. - Number of Steps:
256steps per update. - Batch Size:
128samples per gradient update. - Number of Epochs:
4epochs per batch. - Discount Factor:
0.99to prioritize long-term rewards. - GAE Lambda:
0.95for balanced advantage estimation. - Clip Range:
0.2to maintain stable policy updates. - Entropy Coefficient:
0.01to encourage exploration. - Value Function Coefficient:
0.5for balanced loss. - Maximum Gradient Norm:
0.5to prevent exploding gradients. - Device: Automatically selects GPU if available.
- TensorBoard Log: Specifies the directory for TensorBoard logs.
5.3.2. Running the Training Loop
Once the model is initialized with the appropriate hyperparameters, the next step is to commence the training loop. This involves running the agent through numerous episodes of the Hangman game, allowing it to interact with the environment, learn from rewards, and refine its guessing strategy over time.
Steps to Run the Training Loop:
-
Initialize the Environment:
- Wrap the custom Hangman environment with
DummyVecEnvandVecMonitorto handle vectorized environments and monitor performance metrics.
- Wrap the custom Hangman environment with
-
Define Callbacks:
- Combine custom callbacks (
CurriculumCallback,AverageRewardCallback,CheckpointCallback) usingCallbackListto manage multiple aspects of training simultaneously.
- Combine custom callbacks (
-
Train the Model:
- Invoke the
learnmethod on the model, specifying the total number of timesteps and passing the combined callbacks.
- Invoke the
-
Monitor Progress:
- Utilize TensorBoard and console logs to monitor training progress, average rewards, and phase advancements.
Considerations:
- Total Timesteps: Determines how long the model trains. Higher timesteps generally lead to better performance but require more computational resources.
- Progress Monitoring: Regularly monitoring average rewards and curriculum phases helps in assessing the agent's learning trajectory and making necessary adjustments.
- Checkpointing: Periodically saving the model ensures that progress is not lost and allows for experimentation with different phases or hyperparameters without restarting from scratch.
5.3.3. Code Example: Model Initialization and Training
Below is a comprehensive code example that illustrates the initialization of the Recurrent PPO model and the execution of the training loop. This example integrates the custom environment, policy architecture, callbacks, and training configurations discussed earlier.
# =======================
# Curriculum Management
# =======================
# Initialize the Curriculum instance
curriculum = Curriculum()
# =======================
# Hangman Environment
# =======================
# Assume 'word_list' is already loaded and cleaned from the previous sections
word_list = cleaned_word_list # From section 3.2.3
max_word_length = 20
# Initialize the training environment with curriculum
env = HangmanEnv(word_list=word_list, curriculum=curriculum, max_word_length=max_word_length)
# Check the environment for compatibility
check_env(env)
# =======================
# Policy Keyword Arguments
# =======================
policy_kwargs = dict(
activation_fn=nn.ReLU,
net_arch=dict(pi=[256, 128], vf=[256, 128]),
lstm_hidden_size=128,
n_lstm_layers=1,
shared_lstm=True,
enable_critic_lstm=False,
)
# =======================
# Custom Callbacks
# =======================
from stable_baselines3.common.callbacks import CallbackList, CheckpointCallback
# Define when to advance phases (e.g., after 800k, 1.6M, 2.4M, 3.2M, and 4M timesteps)
phase_timesteps = [800_000, 1_600_000, 2_400_000, 3_200_000, 4_000_000]
# Initialize the CurriculumCallback
curriculum_callback = CurriculumCallback(
curriculum=curriculum,
phase_timesteps=phase_timesteps,
verbose=1
)
# Initialize the AverageRewardCallback
average_reward_callback = AverageRewardCallback(check_freq=5000, verbose=1)
# Define the CheckpointCallback to save models periodically
checkpoint_callback = CheckpointCallback(
save_freq=50_000, # Save every 50,000 steps
save_path='./PPO_LSTM_MORE_ROUNDS/', # Directory to save models
name_prefix='hangman_model_PPO_LSTM', # Prefix for saved model files
save_replay_buffer=False, # Not needed for PPO
save_vecnormalize=False # Not needed if VecNormalize not used
)
# Combine all callbacks
callback = CallbackList([curriculum_callback, average_reward_callback, checkpoint_callback])
# =======================
# Vectorized Environment
# =======================
from stable_baselines3.common.vec_env import VecMonitor
# Wrap the training environment
vec_train_env = DummyVecEnv([lambda: env])
vec_train_env = VecMonitor(vec_train_env)
# =======================
# Device Configuration
# =======================
# Check if GPU is available
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# =======================
# Model Initialization
# =======================
model = RecurrentPPO(
"MlpLstmPolicy",
vec_train_env,
policy_kwargs=policy_kwargs,
learning_rate=1e-4,
n_steps=256,
batch_size=128,
n_epochs=4,
gamma=0.99,
gae_lambda=0.95,
clip_range=0.2,
ent_coef=0.01,
vf_coef=0.5,
max_grad_norm=0.5,
verbose=0,
device=device,
tensorboard_log="./PPO_Hangman_tensorboard/"
)
# =======================
# Training the Model
# =======================
# Define total timesteps for training
total_timesteps = 10_000_000 # Adjust as needed based on computational resources
# Start training
model.learn(total_timesteps=total_timesteps, callback=callback, progress_bar=True)
Explanation:
-
Curriculum Initialization:
- Creates an instance of the
Curriculumclass to manage training phases.
- Creates an instance of the
-
Environment Setup:
- Initializes the
HangmanEnvwith the cleaned word list and curriculum. - Checks the environment for compliance with Gymnasium standards using
check_env.
- Initializes the
-
Policy Configuration:
- Defines
policy_kwargswith the desired activation function, network architecture, and LSTM configurations.
- Defines
-
Callback Initialization:
- Sets up the
CurriculumCallbackto advance training phases at specified timesteps. - Sets up the
AverageRewardCallbackto monitor and log average rewards every 5,000 steps. - Sets up the
CheckpointCallbackto save the model every 50,000 steps. - Combines all callbacks into a
CallbackListfor streamlined integration.
- Sets up the
-
Vectorized Environment:
- Wraps the custom environment with
DummyVecEnvandVecMonitorto facilitate compatibility with Stable Baselines3 and to monitor performance metrics.
- Wraps the custom environment with
-
Device Configuration:
- Automatically selects GPU (
cuda) if available for accelerated training; otherwise, defaults to CPU.
- Automatically selects GPU (
-
Model Initialization:
- Creates an instance of
RecurrentPPOwith the specified policy architecture and hyperparameters. - Specifies the directory for TensorBoard logs to monitor training progress visually.
- Creates an instance of
-
Training Loop:
- Defines the total number of timesteps (
10,000,000) for training. Adjust this value based on available computational resources and desired training duration. - Initiates the training process using the
learnmethod, integrating the combined callbacks and enabling the progress bar for real-time monitoring.
- Defines the total number of timesteps (
Notes:
- TensorBoard Integration: By specifying the
tensorboard_logparameter, you can visualize training metrics in real-time using TensorBoard. Launch TensorBoard by running:
tensorboard --logdir=./PPO_Hangman_tensorboard/
-
Checkpoint Directory: Ensure that the directory specified in
save_path(./PPO_LSTM_MORE_ROUNDS/) exists or will be created to store model checkpoints. -
Adjusting Timesteps: The
total_timestepsparameter can be modified based on how long you wish to train the agent. Longer training periods typically result in better performance but require more computational time. -
Verbose Levels: Setting
verbose=1in callbacks provides detailed logs during training, which can be helpful for debugging and monitoring progress.
By meticulously configuring the policy architecture, setting up effective callbacks, and initializing the Recurrent PPO model with appropriate hyperparameters, we establish a robust framework for training our Hangman AI. This structured approach ensures that the agent learns efficiently, adapts its strategies over time, and steadily improves its performance in the game.
With the reinforcement learning model successfully integrated and the training loop in place, our Hangman AI is now set to embark on its learning journey. In the next section, we'll explore how to evaluate and test the AI agent, assessing its performance and fine-tuning its strategies to achieve mastery in the game of Hangman.
6 - Evaluating and Testing the AI Agent
After training our Hangman AI, it's crucial to assess its performance to ensure it has learned effective strategies and can generalize its knowledge to new, unseen words. In this section, we'll delve into various evaluation and testing methodologies, including defining performance metrics, validating the agent with a dedicated test set, and visualizing its decision-making processes. These evaluations will provide insights into the AI's strengths and areas for improvement, guiding further refinements.
6.1. Performance Metrics for Hangman AI
To comprehensively evaluate our Hangman AI, we must establish clear and relevant performance metrics. These metrics will quantify the agent's effectiveness and efficiency in playing the game, providing measurable indicators of its proficiency.
6.1.1. Win Rate and Efficiency
- Win Rate: Provides a direct measure of the agent's ability to solve the game under varying conditions.
- Efficiency: Highlights the agent's ability to optimize its guessing strategy, reducing the number of unnecessary attempts. Learn more about performance metrics in Performance Measurement.
Calculating Win Rate and Efficiency:
-
Win Rate Calculation:
Win Rate (%) = (Number of Wins / Total Number of Games) × 100 -
Average Steps per Game:
Average Steps = (Sum of Steps in Each Game) / Total Number of Games
Importance:
- Win Rate: Provides a direct measure of the agent's ability to solve the game under varying conditions.
- Efficiency: Highlights the agent's ability to optimize its guessing strategy, reducing the number of unnecessary attempts.
By monitoring these metrics, we can gauge the AI's overall performance and identify trends or patterns that may require further optimization.
6.1.2. Average Steps per Game
Average Steps per Game quantifies the average number of guesses the AI makes to solve a game. This metric offers insights into the agent's guessing strategy's effectiveness and efficiency.
Benefits:
- Strategy Optimization: A lower average indicates that the AI is making more informed and strategic guesses, minimizing redundant or ineffective attempts.
- Resource Utilization: Efficient strategies conserve computational resources and time, especially when scaling to larger datasets or more complex games.
- Comparative Analysis: Facilitates comparisons between different training configurations, policies, or model architectures to determine which setups yield more efficient agents.
Implementation Considerations:
- Tracking Steps: Ensure that each game session accurately tracks the number of steps taken by the agent.
- Data Aggregation: Accumulate step counts across multiple games to compute a reliable average.
- Handling Outliers: Consider excluding games with excessively high step counts that may skew the average, ensuring a more representative metric.
By integrating the average steps per game alongside the win rate, we obtain a holistic view of the AI's performance, balancing both success frequency and operational efficiency.
6.2. Validation with a Test Set
Validating the AI agent with a dedicated test set is essential to assess its ability to generalize beyond the training data. This process involves evaluating the agent's performance on a separate set of words it hasn't encountered during training, ensuring unbiased and comprehensive assessment.
6.2.1. Preparing the Validation Set
A robust validation set should encompass a diverse range of words differing in length, complexity, and linguistic patterns. Here's how to prepare an effective validation set:
-
Word Selection:
- Random Sampling: Randomly select words from the cleaned word list to ensure diversity.
- Balanced Representation: Ensure the set includes a balanced mix of word lengths and complexities across different curriculum phases.
-
Size Determination:
- Sample Size: Choose an appropriate number of words (e.g., 1,000) to provide statistically significant insights without overwhelming computational resources.
- Coverage: Ensure the validation set covers all curriculum phases to evaluate the agent's performance across varying difficulty levels.
-
Isolation from Training Data:
- Exclusion: Ensure that the validation words are not part of the training set to prevent data leakage and biased evaluations.
-
Storage:
- Data Structure: Store the validation words in a list or array for efficient access during evaluation.
- Persistence: Optionally, save the validation set to a file for reproducibility and future assessments.
Example Code:
import random
# Prepare the validation set by randomly sampling 1,000 words from the cleaned word list
validation_words = random.sample(word_list, min(1000, len(word_list)))
Explanation:
- The
random.samplefunction selects a specified number of unique words from theword_list. - The
minfunction ensures that the sample size does not exceed the available words in the list.
By meticulously preparing the validation set, we establish a reliable benchmark to assess the AI's generalization capabilities across a wide spectrum of Hangman scenarios.
6.2.2. Running Evaluation Episodes
With the validation set prepared, the next step is to run evaluation episodes where the AI plays against each word in the set. This process involves resetting the environment with a specific word and allowing the agent to make guesses until the game concludes.
Evaluation Process:
-
Initialization:
- Environment Reset: For each word, reset the Hangman environment, explicitly setting the target word to ensure consistency.
- State Management: Initialize any necessary state variables, such as LSTM states, to maintain continuity across episodes.
-
Gameplay Loop:
- Action Prediction: At each step, use the trained model to predict the next letter guess based on the current observation and internal state.
- Environment Interaction: Execute the predicted action within the environment, receiving updated observations, rewards, and termination signals.
- Termination Check: Continue the loop until the game is won (all letters guessed) or lost (maximum attempts exceeded).
-
Performance Tracking:
- Win Counting: Increment a win counter for each game the AI successfully completes.
- Step Counting: Record the number of steps taken in each game to calculate average steps per game.
-
Result Aggregation:
- Win Rate Calculation: Compute the overall win rate across all evaluation games.
- Efficiency Calculation: Determine the average number of steps the AI takes per game.
Code Example: Evaluation Function
Below is an implementation of the evaluate_agent function, which systematically assesses the AI's performance across the validation set:
from tqdm import tqdm
import numpy as np
def evaluate_agent(model, env, validation_words):
wins = 0
total_games = len(validation_words)
for idx, word in enumerate(tqdm(validation_words)):
# Reset the environment with the validation word
obs, info = env.reset(word=word)
done = False
# Initialize the LSTM states
lstm_states = None # (h, c)
episode_starts = True # True at the beginning of each episode
step_counter = 0
max_steps_per_episode = 1000 # Set a reasonable limit
while not done and step_counter < max_steps_per_episode:
# Predict the action and update the LSTM states
action, lstm_states = model.predict(
obs,
state=lstm_states,
episode_start=np.array([episode_starts]),
deterministic=True
)
obs, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
episode_starts = done # Reset LSTM states if episode is done
step_counter += 1
if step_counter >= max_steps_per_episode:
print(f"Exceeded maximum steps for word '{word}'")
# Check if the agent won
if env.remaining_attempts > 0:
wins += 1
win_percentage = (wins / total_games) * 100
print(f"Agent won {wins} out of {total_games} games.")
print(f"Win percentage: {win_percentage:.2f}%")
Explanation:
-
Function Parameters:
model: The trained Recurrent PPO model.env: The Hangman environment instance.validation_words: A list of words designated for evaluation.
-
Looping Through Validation Words:
- For each word in the validation set, the environment is reset with the target word.
- The agent interacts with the environment, making guesses until the game concludes or a maximum step limit is reached.
- If the agent successfully guesses the word within the allowed attempts, the win counter is incremented.
-
Outcome Reporting:
- After all evaluation games, the function prints the total number of wins and the corresponding win percentage, providing a clear measure of the agent's performance.
# Evaluate the agent using the prepared validation set
evaluate_agent(model, env, validation_words)
Note: The actual win counts and percentages will vary based on the training efficacy and word list characteristics.
By executing this evaluation function, we obtain quantitative metrics that reflect the AI's proficiency in playing Hangman, laying the groundwork for further analysis and optimization.
6.3. Visualizing Agent Performance
Quantitative metrics provide valuable insights, but visualizing the agent's performance can offer deeper understanding into its decision-making processes and strategic behaviors. Visualization aids in identifying patterns, strengths, and weaknesses that may not be apparent through numerical data alone.
6.3.1. Rendering Game States
Rendering game states involves visually displaying the current state of the Hangman game, including the revealed letters, guessed letters, and remaining attempts. This visualization provides a clear, real-time depiction of the AI's progress and decisions throughout the game.
Benefits:
- Human Interpretation: Allows developers and observers to witness the AI's gameplay, facilitating intuitive understanding of its strategies.
- Debugging: Helps identify scenarios where the AI may be making suboptimal or unexpected guesses.
- Engagement: Makes the evaluation process more interactive and engaging, especially when demonstrating the AI's capabilities to others.
Implementation Details:
- Word Display: Show the word with underscores representing unknown letters and actual letters for correct guesses.
- Guessed Letters: List all letters the AI has already guessed, providing context for its current strategy.
- Remaining Attempts: Display the number of incorrect guesses the AI has left before losing the game.
Code Example: Visualization Function
Below is the implementation of the visualize_agent_playing function, which renders the Hangman game as the AI interacts with it:
import time
from tqdm import tqdm
import numpy as np
def visualize_agent_playing(model, env, word):
"""
Visualize the Hangman agent playing a single game.
:param model: Trained RecurrentPPO model.
:param env: Hangman environment.
:param word: The word for the environment to guess.
"""
# Reset the environment with the specified word
obs, info = env.reset(word=word)
done = False
# Initialize LSTM states and flags
lstm_states = None # (h, c)
episode_starts = True # True at the beginning of each episode
step_counter = 0
max_steps_per_episode = 1000 # Set a reasonable limit
print(f"Word to guess: {word}")
print("=" * 30)
while not done and step_counter < max_steps_per_episode:
# Render the current state of the environment
env.render()
# Predict the action and update LSTM states
action, lstm_states = model.predict(
obs,
state=lstm_states,
episode_start=np.array([episode_starts]),
deterministic=True
)
obs, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
episode_starts = done # Reset LSTM states if the episode is done
step_counter += 1
# Sleep to visualize progress
time.sleep(0.5)
# Render the final state of the game
print("\nFinal state:")
env.render()
# Display result
if env.remaining_attempts > 0:
print("\nThe agent won!")
else:
print("\nThe agent lost!")
print("=" * 30)
Explanation:
-
Function Parameters:
model: The trained Recurrent PPO model.env: The Hangman environment instance.word: The specific word the agent will attempt to guess.
-
Gameplay Visualization:
- Environment Reset: The environment is reset with the chosen word to ensure a controlled and reproducible game state.
- Rendering Loop: In each step, the environment's current state is rendered, displaying the revealed word, guessed letters, and remaining attempts.
- Action Prediction: The model predicts the next letter to guess based on the current observation and internal state.
- Step Execution: The predicted action is executed within the environment, updating the game state accordingly.
- Progress Delay: A short delay (
time.sleep(0.5)) is introduced to make the visualization observable in real-time.
-
Outcome Display:
- After the game concludes, the final state is rendered, and the result (win or loss) is displayed, providing a complete overview of the AI's performance in that particular game.
Usage:
import random
# Example usage: Visualize the agent playing with a randomly selected word
random_word = random.choice(word_list)
print(random_word)
# Visualize the agent's gameplay
visualize_agent_playing(model, env, random_word)
Sample Output:
example
Word to guess: example
==============================
Word: e _ a _ _ _ e
Guessed Letters: ['e']
Remaining Attempts: 12
Word: e x a _ _ _ e
Guessed Letters: ['e', 'x']
Remaining Attempts: 12
Word: e x a m _ _ e
Guessed Letters: ['e', 'x', 'a', 'm']
Remaining Attempts: 12
Word: e x a m p _ e
Guessed Letters: ['e', 'x', 'a', 'm', 'p']
Remaining Attempts: 12
Word: e x a m p l e
Guessed Letters: ['e', 'x', 'a', 'm', 'p', 'l']
Remaining Attempts: 12
Final state:
Word: e x a m p l e
Guessed Letters: ['e', 'x', 'a', 'm', 'p', 'l']
Remaining Attempts: 12
The agent won!
==============================
Evaluating and testing the Hangman AI is a pivotal step in ensuring its effectiveness and reliability. By establishing clear performance metrics, validating the agent with a dedicated test set, and visualizing its gameplay, we gain comprehensive insights into its strengths and areas for improvement. These evaluations not only affirm the AI's current capabilities but also guide future enhancements, fostering continuous learning and optimization.
Conclusion
Congratulations! You've successfully journeyed through the process of building a sophisticated Hangman AI using Reinforcement Learning. From setting up the development environment and crafting a custom Gymnasium environment to integrating a Recurrent PPO model and rigorously evaluating its performance, each step has equipped you with valuable insights and hands-on experience in advanced machine learning techniques.
Key Takeaways
-
Custom Environment Design: Creating a tailored Gymnasium environment allowed for precise control over the Hangman game's dynamics, ensuring that the AI agent receives comprehensive and relevant information to make informed guesses.
-
Curriculum Learning Implementation: By structuring the training process into progressive phases of increasing difficulty, you enabled the AI to build foundational strategies before tackling more complex challenges, mirroring effective human learning practices.
-
Recurrent PPO Integration: Leveraging the power of Recurrent PPO with an
MlpLstmPolicyequipped the agent with memory capabilities, allowing it to remember past actions and adapt its strategy based on the evolving game state. -
Robust Evaluation: Through meticulous performance metrics, validation with a dedicated test set, and visualization of the agent's gameplay, you ensured that the AI not only performs well in controlled environments but also generalizes effectively to new, unseen words.
Future Directions
While the Hangman AI developed in this project demonstrates impressive capabilities, there's always room for enhancement:
-
Enhanced State Representation: Incorporating more nuanced features, such as positional letter probabilities or contextual hints, could further refine the agent's guessing strategy.
-
Scalability: Expanding the word list to include multilingual dictionaries or domain-specific vocabularies can test the AI's adaptability across different linguistic contexts.
-
User Interaction: Developing an interactive interface where users can play against the AI or visualize its decision-making in real-time can make the project more engaging and accessible.
Explore the Project
Ready to dive deeper? Access the complete source code, detailed documentation, and ongoing updates on our GitHub repository. Whether you're looking to experiment with the AI, contribute to its development, or adapt it for your unique applications, the repository is your gateway to all things Hangman AI.
Check out the Hangman PPO LSTM GitHub RepositoryThank you for following along! We hope this project has enriched your understanding of Reinforcement Learning and inspired you to embark on your own AI adventures. Feel free to reach out with questions, feedback, or contributions---let's continue building intelligent systems together.
Happy Coding!
🔙 Back to all blogs | 🏠 Home Page
About the Author

Sagarnil Das
Sagarnil Das is a seasoned AI enthusiast with over 12 years of experience in Machine Learning and Deep Learning.
Some of his other accomplishments includes:
- Ex-NASA researcher
- Ex-Udacity Mentor
- Intel Edge AI scholarship winner
- Kaggle Notebooks expert
When he's not immersed in data or crafting AI models, Sagarnil enjoys playing the guitar and doing street photography.
An avid Dream Theater fan, he believes in blending logic with creativity to solve complex problems.
You can find out more about Sagarnil here.To contact him regarding any guidance, questions, feedbacks or challenges, you can contact him by clicking the chat icon on the bottom right of the screen.
Connect with Sagarnil: